Meine Rolle als Senior Data Strategist / Data Governance Architect interpretiere ich als strategischer Brückenbauer zwischen IT, Management und Fachbereichen. Meine Hauptaufgaben umfassen die ganzheitliche Analyse gewachsener, fragmentierter Datenlandschaften, die Entwicklung eines zukunftsfähigen Zielbildes samt Roadmap sowie den Aufbau von Data-Governance-Strukturen und Rollenmodellen (z. B. Data Owner und Data Steward).
Profitieren Sie von meiner Erfahrung in diversen Projekten mit Bezug zu Unternehmensarchitektur, Datenstrategie und KI. Aktuelle Ergebnisse und weitere Vorhaben bei meinen Kunden aus den Branchen Automotive, Finance, und HealthCare weisen alle in dieselbe Richtung, wenn auch mit unterschiedlichem Grad des Fortschritts und Geschwindigkeit bei der Veränderbarkeit: Datenmanagement und KI sind untrennbar miteinander verbunden und gestalten als Fundament eine wirtschaftlich erfolgreiche Zukunft mit.
Auswahl zugehöriger Projekthemen:
- Bestandsaufnahme der Datenlandschaft in Form von Datenobjekten und Informationsflüssen zwischen Applikationen
- Umsetzung von Data & AI Governance gekoppelt mit Daten- und KI-Architektur (IST vs SOLL) zur Planung und Harmonisierung aktueller Initiativen.
- Demokratisierung der Geschäftsobjektmodellierung und Zugriff für alle Mitarbeiter durch Einführung einer Datenmanagementplattform (Business Object Navigator, eine Ontologie je Business Object).
- Einführung EIA (Enterprise Information Architecture) mit unternehmensweitem Geschäftsobjektkatalog, Blueprints für umsetzende Anwendungen und rollenbasierter Governance (Data Owner = Product Owner, Data Steward / Data Architect).
- Kollaborative Modellierung von Geschäftsobjekten für Produkt-Teams mit Abgleich konzeptioneller, fachlicher und physischer Sichten. Erreichung hoher und breiter Akzeptanz durch die Produkt-Teams bis hin zur selbstständigen Weiterentwicklung.
- Erarbeitung von Lösungsanforderungen, Evaluierung Tool-Kandidaten (long List, short List), Auswahl, Pilotierung, Einführung, Ausbau im Bereich Unternehmensarchitektur und Data Management.
Um dieses Profil in den Kontext des aktuellen Standes der Technik einzuordnen, müssen moderne Architekturparadigmen, die Integration von Künstlicher Intelligenz (KI) und aktuelle regulatorische Anforderungen berücksichtigt werden:
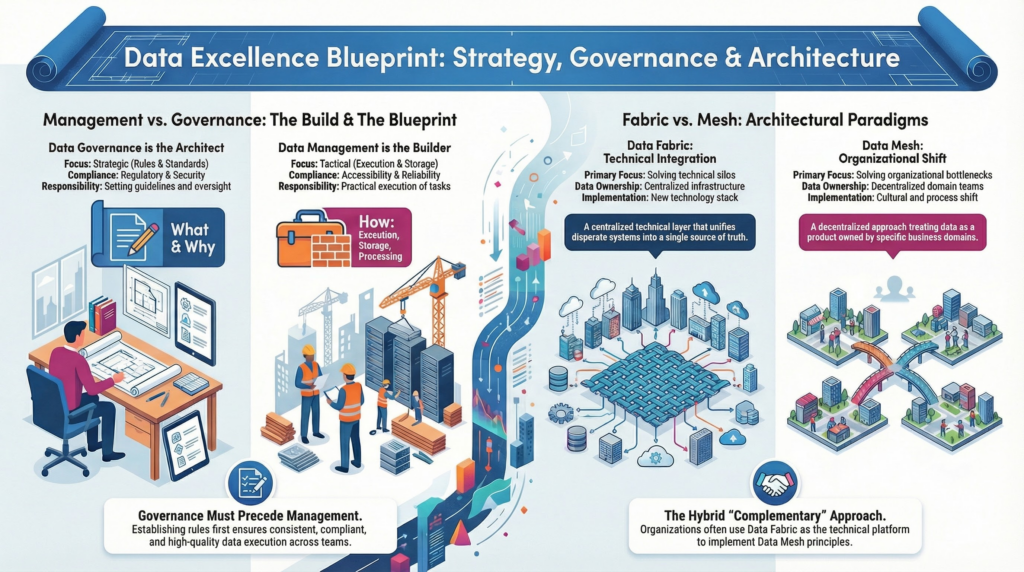
1. Moderne Zielarchitekturen: Data Fabric und Data Mesh Um historisch gewachsene Datensilos (sogenannte „Data Swamps“) aufzubrechen, setzt der aktuelle Stand der Technik auf die Kombination zweier komplementärer Ansätze:
- Data Fabric (Die technologische Schicht): Hierbei handelt es sich um eine intelligente, plattformübergreifende Integrationsschicht, die Metadaten nutzt, um Daten unabhängig von ihrem physischen Speicherort nahtlos zu verbinden und Prozesse mithilfe von KI zu automatisieren.
- Data Mesh (Das organisatorische Paradigma): Dieser dezentrale Ansatz verlagert die Datenverantwortung in die Fachbereiche (Domain-driven Ownership) und behandelt Daten als Produkte. Es erfordert eine Self-Service-Infrastruktur und eine föderierte Governance, bei der globale Standards gemeinsam definiert, aber lokal in den Domänen umgesetzt werden. Ein Data Strategist muss evaluieren, wie diese Konzepte im Unternehmen in logische Datenmodelle und strukturierte Datenflüsse übersetzt werden können.
2. KI-Readiness und Agentic AI im Datenmanagement Der Einzug von KI stellt sowohl den größten Treiber als auch den größten Nutznießer einer modernen Datenstrategie dar.
- AI-Ready Data: Eine Kernaufgabe des Governance-Architekten ist es, die Datenbestände für KI-Workloads zu qualifizieren. Dies bedeutet, eine extrem hohe Datenqualität sicherzustellen, Bias (Verzerrungen) in den Trainingsdaten zu vermeiden und eine lückenlose Dokumentation der Datenherkunft (Data Lineage) zu gewährleisten.
- KI als Werkzeug (Agentic AI): Der Stand der Technik erlaubt es heute, KI-Technologien einzusetzen, um das Datenmanagement selbst zu professionalisieren. KI-Agenten können Aufgaben wie die automatisierte Datenklassifizierung, das Metadaten-Harvesting und die kontinuierliche Anomalie-Erkennung übernehmen, wodurch die Governance effizient und skalierbar wird.
3. Strenge Regulatorik: EU AI Act und Data Act Die strategische Ausrichtung von Datenlandschaften wird massiv durch neue gesetzliche Rahmenbedingungen geprägt. Der EU AI Act fordert bei KI-Systemen eine strenge, risikobasierte Governance und Transparenz. Er verlangt hochwertige, fehlerfreie Datensätze sowie die Erklärbarkeit, welche Daten zu welchen KI-Entscheidungen geführt haben. Der Data Act zielt zudem auf die Förderung der Datenökonomie durch einen erleichterten Datenaustausch und die Vermeidung von Vendor-Lock-ins ab. Eine moderne Data-Governance-Strategie muss diese regulatorischen Leitplanken von Beginn an als Fundament (“Compliance by Design”) integrieren.
4. Kultureller Wandel und Data Literacy Neben der Konzeption von Architekturen und der Evaluation von Lösungen (z. B. durch Mini-POCs) ist der Senior Data Strategist primär ein Change Manager. Technologische Transformationen scheitern häufig an fehlender Nutzerakzeptanz und verkrustetem Silodenken. Daher ist die Förderung einer ausgeprägten Datenkultur und „Data Literacy“ (Datenkompetenz) auf allen Ebenen unabdingbar. Der Architekt muss in Workshops moderieren, die Fachbereiche als „Co-Builder“ in die Strategie einbeziehen und den geschäftlichen Mehrwert (ROI) der Dateninitiativen gegenüber dem Management klar kommunizieren.
Zusammenfassend erfordert das Profil des Senior Data Strategist / Data Governance Architect heute die Fähigkeit, das „Warum“ und „Wohin“ einer Datenstrategie mit den hochaktuellen Anforderungen von dezentralen Architekturen (Data Mesh), KI-Einsatz und europäischer Regulatorik in Einklang zu bringen und dies in ein pragmatisches, umsetzbares Zielbild zu übersetzen.