#feature #lifecycle #tracing
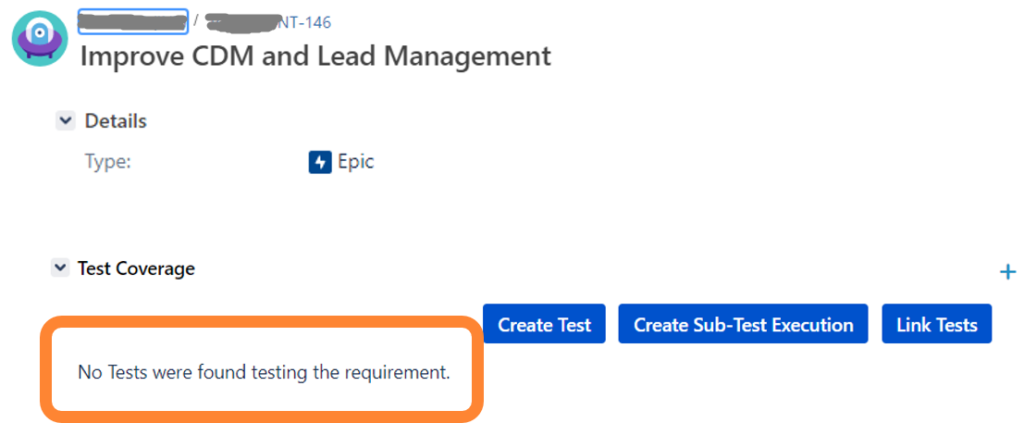
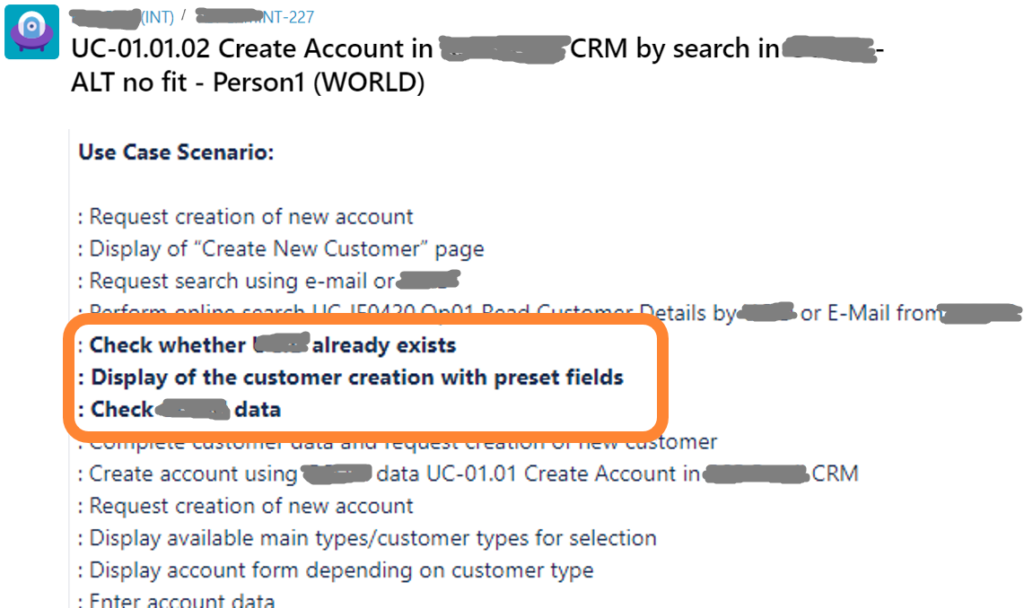
When changing your application landscape on a bigger scale you might have to worry about a target architecture that you can only reach with intermediate steps like per year or release. Even a high-level roadmap may be rather complex due to necessary plan changes. The following reduced example shows the core problem:
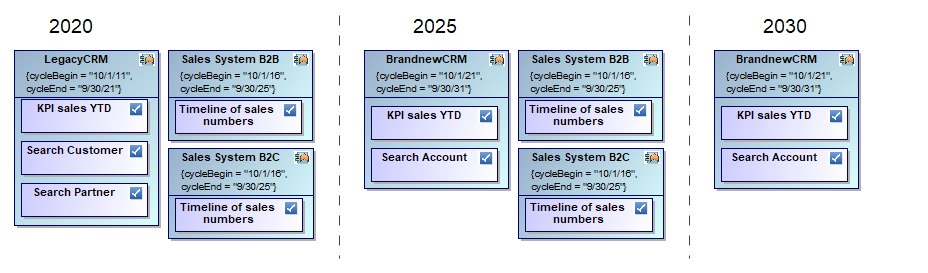
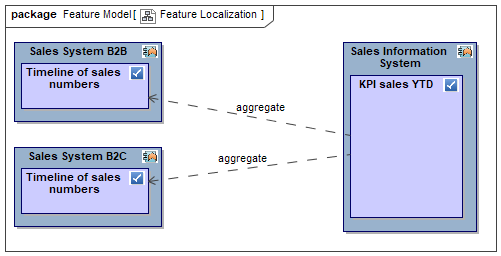
As you see, applications are repeated in different time windows and so are the features they provide. Moreover, feature provisioning may change like “Duplicate Check” might move from “LegacyCRM” to “BrandnewCMR”. In addition, features themselves may change like “Search Customer” and “Search Partner” being merged into “Search Account”.
I see people doing these things in Excel and Visio or, even worse, in Powerpoint. And everytime my hair stands up expecting a lot of waste or worse like lost COVID-19 results. Excel is a powerful thing, no doubt, but it has its limits. The right way to do such an exercise is using a proper method with a proper tool set. There are many options like application lifecycle tools, enterprise architecture management tools, and modeling tools. I will explain the core concept using a modeling tool, but it can easily be translated to other tools.
The core concept is based on adding the notion of lifecycle or time in general to your plan elements. Each gets a begin and end date between which it is valid. Consequently, showing an application being valid from 2018 to 2022 in a plan scenario for 2025 is not valid because it is long gone. But, since applications and also features typically live for many years, we can save a lot of redundancy by reusing the same elements wherever valid which also drastically improves consistency of your plan.
Now, you can understand much better how we build the diagram from above. In fact, our database contains less elements and relations than you count on the diagram since we simply reuse them where valid.
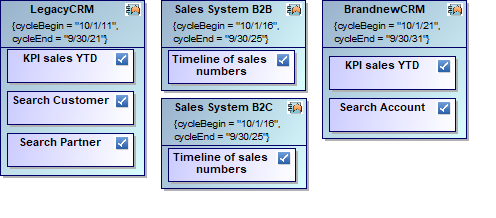
You may already guess the drastic improvement you can achieve in your very probably much larger scenario. It’s getting even better because we are now able to improve data quality with data validation as well as Powerpoint slides and Excel sheets by simply getting those as results of reports. We can even transfer plan data from and to other tools if necessary like for requirements management or budget planning.