The Problem
Language models are everywhere now. People praise them, but also complain about responses—unreliable, hallucination, cannot let it work alone, and so on. These systems, capable of understanding and generating human-like text, are often called copilots—a term borrowed from aerospace or car racing. That term indicates their main expected role being support for the pilot.
But how do we actually classify what these models can do? And more importantly, how much can we trust them?
A Hybrid Classification Framework
Drawing inspiration from the SAE levels of driving automation and grounded in human-computer interaction research on trust in automation, we propose a two-dimensional framework for classifying language models:
- Operational Autonomy – adapted from SAE Levels (0–5): What can the model do on its own?
- Cognitive Trust and Delegation – how much mental effort does the user expend, and how much responsibility is delegated?
Each level in the chart below reflects both dimensions.
| Level | Autonomy Description | Trust/Delegation Role |
|---|---|---|
| 0 – Basic Support | Passive tools like spellcheckers; no real autonomy | No Trust: User must fully control and interpret everything |
| 1 – Assisted Generation | Suggests words or phrases (autocomplete); constant oversight needed | Suggestive Aid: User supervises and approves each suggestion |
| 2 – Semi-Autonomous Text Production | Generates coherent content from prompts (emails, outlines); needs close supervision | Co-Creator: User relies in low-stakes tasks but reviews all outputs |
| 3 – Context-Aware Assistance | Can handle structured tasks (e.g., medical summaries); users remain alert | Delegate: User lets go during routine tasks but monitors for failure |
| 4 – Fully Autonomous Within Domains | Works independently in narrow contexts (e.g., customer service bot) | Advisor: Trusted within scope; user rarely intervenes |
| 5 – General Language Agent | Hypothetical general-purpose assistant capable across domains without oversight | Agent: Fully trusted to operate independently and responsibly |
Why SAE Levels Make Sense
While not acting in the physical world, it makes perfect sense to compare language models to autonomous vehicles in terms of their capabilities and limitations. The SAE classification helps clarify expectations, safety considerations, and technological milestones.
Let’s first briefly revisit what each SAE level entails for automobiles:
- Level 0 (No Automation): The human driver does everything; no automation features assist with driving beyond basic warnings.
- Level 1 (Driver Assistance): The vehicle offers assistance with either steering or acceleration/deceleration but requires constant oversight.
- Level 2 (Partial Automation): The system can manage both steering and acceleration but still requires the human to monitor closely.
- Level 3 (Conditional Automation): The vehicle handles all aspects of driving under specific conditions; the human must be ready to intervene if necessary.
- Level 4 (High Automation): The car can operate independently within designated areas or conditions without human input.
- Level 5 (Full Automation): Complete autonomy in all environments—no human intervention needed.
Adapting Levels to Language Models
Level 0: Basic Support
At this foundational level, language models serve as simple tools—spell checkers or basic chatbots—that provide minimal assistance without any real understanding or autonomy. They do not generate original content on their own but act as aids for humans who make all decisions.
Example: Elementary grammar correction programs that flag mistakes but don’t suggest nuanced rewrites.
Level 1: Assisted Generation
Moving up one step, some language models begin offering suggestions based on partial input. For example, autocomplete functions in email clients that predict next words or phrases fall into this category—they assist but require constant supervision from users who must review outputs before accepting them.
Example: Gmail’s smart compose feature.
Level 2: Semi-Autonomous Text Production
At this stage, models can generate longer stretches of coherent text when given prompts—think about AI tools that draft emails or outline articles—but they still demand continuous oversight. Users need to supervise outputs actively because errors such as factual inaccuracies or inappropriate tone remain common pitfalls.
Example: ChatGPT generating email drafts or article outlines.
Level 3: Context-Aware Assistance
Now we reach an intriguing analogy with conditional automation—where AI systems can handle complex tasks within certain constraints yet require humans to step back temporarily while remaining alert for potential issues. Large language models operating at this level might manage summarization tasks under specific domains (e.g., medical summaries) but could falter outside their trained scope.
Example: Medical AI assistants that can summarize patient records but require doctor oversight.
Level 4: Fully Autonomous Within Domains
Imagine an AI-powered assistant capable of managing conversations entirely within predefined contexts—say customer service bots handling standard inquiries autonomously within specified industries—but unable beyond those limits without retraining or manual intervention.
Example: Customer service chatbots for specific industries like banking or retail.
Level 5: Fully Autonomous General Language Understanding
Envisioning true “full autonomy” for language models means creating systems that understand context deeply across countless topics and produce accurate responses seamlessly everywhere—all without prompting from humans if desired. While such systems remain theoretical today, research aims toward developing general-purpose AI assistants capable not only of conversing fluently across domains but doing so responsibly without oversight.
Example: Theoretical future AI systems that could operate across all domains without human oversight.
Current State and Implications
Now that we have a clear classification framework, let’s examine where we stand today and what this means for practical applications.
What does this classification tell us about our current standing? Most contemporary large-scale language models sit somewhere around Levels 2 or early-Level 3—they generate impressive content when given prompts yet still struggle with consistency outside narrow contexts and require vigilant supervision by humans who evaluate accuracy critically.
However, there’s an important limitation to the SAE analogy that we need to address.
The Trust Dimension
While the SAE levels offer a useful metaphor for understanding increasing autonomy, they aren’t a perfect fit for language models because:
- Language models don’t act in the physical world themselves—humans interpret and act on their outputs
- Risk and impact in NLP are mediated by human cognition and behavior, unlike the immediate physical risks of self-driving cars
- Autonomy in NLP often deals more with semantic understanding, trustworthiness, context handling, and ethical alignment than sensor-actuator loops
Therefore, I also propose a mapping of the SAE levels to trust levels taking into account cognitive load and responsibility:
- Level 0: No trust: tool offers isolated corrections, requires full user oversight (spellcheck)
- Level 1: Suggestive aid: user must review and approve every suggestion (autocomplete)
- Level 2: Co-creator: user maintains active oversight, only defers in low-stakes contexts (drafting emails)
- Level 3: Delegate: user maintains regular oversight with frequent spot checks and validation (10-20% review)
- Level 4: Advisor: user maintains strategic oversight with periodic reviews (5-10% audit), especially for high-stakes outputs
- Level 5: Agent: user maintains governance oversight with systematic audits (1-5% review) despite autonomous operation
Practical Implications
Classifying language models along SAE-like levels provides practical benefits:
- Common vocabulary for developers, researchers, policymakers, and end-users
- Realistic expectations about capabilities—the difference between tools assisting writing versus fully automating complex decision-making processes
- Regulatory guidance for ensuring safe deployment at each stage
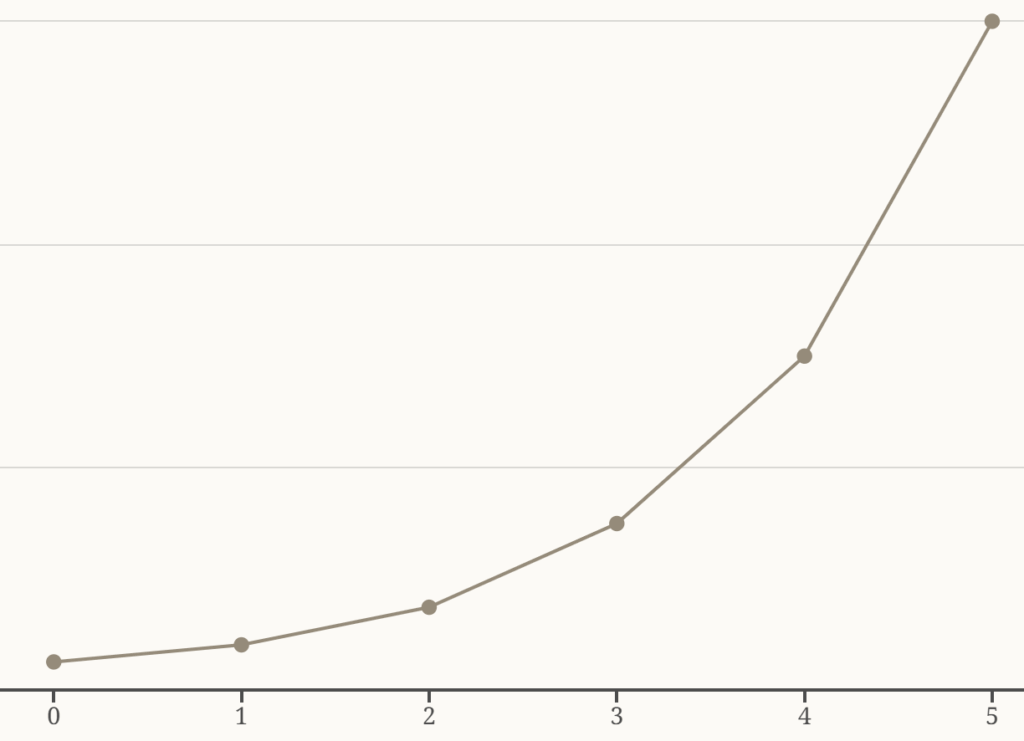
- Effort per level is increasing, probably exponentially
Design Priorities
It’s vital not simply to categorize these technologies for academic interest but also because such clarity informs design priorities:
- Should future efforts focus on improving reliability before granting more independence?
- How do safety concerns evolve as we move up each level?
- What ethical considerations arise when deploying increasingly autonomous NLP systems?
Each incremental step toward higher levels demands careful consideration regarding:
- Transparency: Can users understand when they’re interacting with an assistant versus an agent?
- Accountability: Who bears responsibility if an AI-generated statement causes harm?
Conclusion
Applying SAE-level classifications offers more than just terminology—it provides a roadmap illustrating how far we’ve come and how much further we need to go in developing intelligent language systems capable not only of mimicking human conversation but doing so responsibly across diverse environments.
Recognizing where current technology resides on this spectrum enables us all—from engineers designing smarter assistants to regulators crafting informed policies—to make conscious choices grounded in realistic assessments rather than hype or fear.
As artificial intelligence continues its ascent along these levels—from rudimentary support towards full autonomy—the journey will demand ongoing collaboration among technologists, ethicists, policymakers, and ultimately society itself to ensure these powerful tools serve humanity’s best interests every step along the way.
References
SAE J3016™. “Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles.” First published: 2014. Most recent version (as of 2024): SAE J3016_202104 (April 2021). 🔗 https://www.sae.org/standards/content/j3016_202104/
Hoffman, R. R., Johnson, M., Bradshaw, J. M., & Underbrink, A. (2013). “Trust in automation.” IEEE Intelligent Systems, 28(1), 84–88. DOI: 10.1109/MIS.2013.24